진학사 블랙라벨사업부가 2026학년도 대학수학능력시험 국어영역 시험지를 챗GPT에게 풀게 한 결과, 동일한 모델, 동일한 시험지임에도 불구하고 지시(프롬프트) 방식에 따라 성적이 9등급부터 1등급까지 극단적으로 달라지는 현상이 확인됐다.
챗GPT의 능력보다 ‘무엇을 어떻게 시켰느냐’가 성능을 결정하는 핵심 요인임을 보여주는 실험 결과다.
○ 실험, 세 방식으로 나눠 진행
실험에는 챗GPT의 ChatGPT 5.1 Auto 모드가 사용됐으며, 변수는 지시 방식뿐이었다. 실험은 △시험지 전체를 이미지 파일로 제공한 후 정답만 요구한 A 방식 △문항 세트별 PDF 제공 후 정답만 요구한 B 방식 △세트별 PDF 제공과 함께 단계별 풀이를 요구한 C 방식 등 세 가지 방식으로 나뉘어 진행됐다.
시험지는 2026학년도 수능 국어 영역(홀수형)으로, 공통과목(1~34번(76점))과 선택과목(화법과 작문, 언어와 매체 각 35~45번(24점))으로 구성됐다.
※ 진학사가 챗GPT에게 수능 국어문제 풀이를 지시한 각 실험 방식의 차이
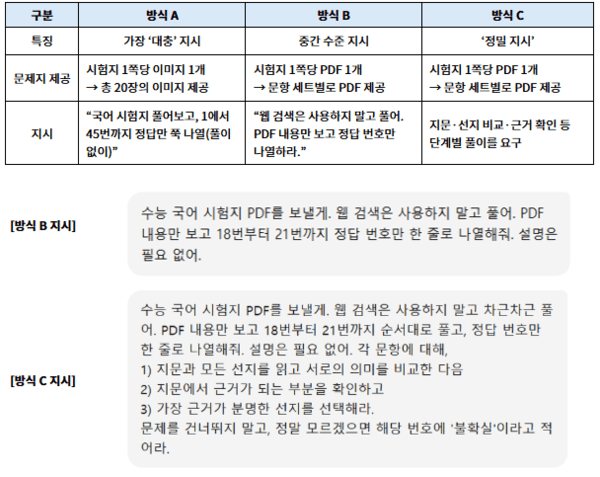
그 결과, A 방식의 점수는 공통 3점, 화법과 작문 5점, 언어와 매체 4점에 그쳤다. B 방식은 공통 39점, 화작 14점, 언매 6점으로 성적이 크게 상승했다. C 방식은 공통 74점, 화작 21점, 언매 14점으로 가장 높은 점수를 기록했다.
진학사 기준 등급 환산에서도 격차는 크게 나타났다. ‘공통+화작’ 기준으로 A 방식은 8점(9등급), B 방식은 53점(5등급), C 방식은 95점(1등급)으로 평가됐다. ‘공통+언매’ 기준 역시 A 방식은 9등급, B 방식은 6등급, C 방식은 1등급으로 나타났다.
즉, 동일한 GPT 모드를 사용했음에도 지시 방식 차이만으로 9등급부터 1등급까지 성적이 갈린 것.
※ 각 실험 방식에 따른 결과

○ 실제 국어시험 풀이전략 적용한 C방식, 가장 우수
세 실험 모두 동일 모델을 통해 진행됐으나, 결과 차이는 모델 능력의 차이가 아니라 지시의 차이에서 비롯되었다.
‘정답만 말해달라’고 요구한 A 방식에서 챗GPT는 최소한의 추론만 수행했다. B 방식은 세트별 구조가 추가됐으나 여전히 얕은 추론만 수행했다. 실제 국어시험 풀이 전략을 강제로 적용한 C 방식에선 성능이 급상승했다.
또한 흥미롭게도, 방식 B에서 정답을 맞힌 문항을 방식 C 에서는 오히려 틀리는 경우가 발생하였다. 이는 챗GPT가 ‘정밀 절차’를 따르는 과정에서 인간이 예상하지 못한 방식으로 판단 경로가 바뀌거나, 근거 해석을 지나치게 복잡하게 처리하면서 오류로 이어질 수 있음을 보여준다.
○ 챗GPT, 머리는 좋지만 말귀는 잘 못 알아들어
이번 실험은 GPT의 성능이 모델 자체보다 ‘사용자가 어떤 방식으로 지시를 내리느냐’에 훨씬 깊이 의존한다는 사실을 확인한 사례다. 대충 말하면 대충 답하고 정확히 말하면 더 정확히 답하지만, 너무 복잡하게 말하면 오히려 혼란을 느끼고 다른 실수를 한다.
진학사 블랙라벨사업부는 “같은 모델이라도 어떤 방식으로 지시하느냐에 따라 성능이 크게 달라진다”며 “AI는 높은 지능을 갖고 있지만 지시를 정교하게 이해하는 능력은 아직 충분하지 않은 만큼, 사용자 프롬프트 설계가 성능 차이를 만드는 핵심 요소”라고 설명했다.